搜狗输入法怎么智能纠错?
搜狗输入法通过智能纠错算法,实现对拼写错误、笔误和常见错别字的自动识别与修正。它利用大数据词库和上下文语义分析,结合用户输入习惯,自动推荐正确词语,提高输入准确率和效率。
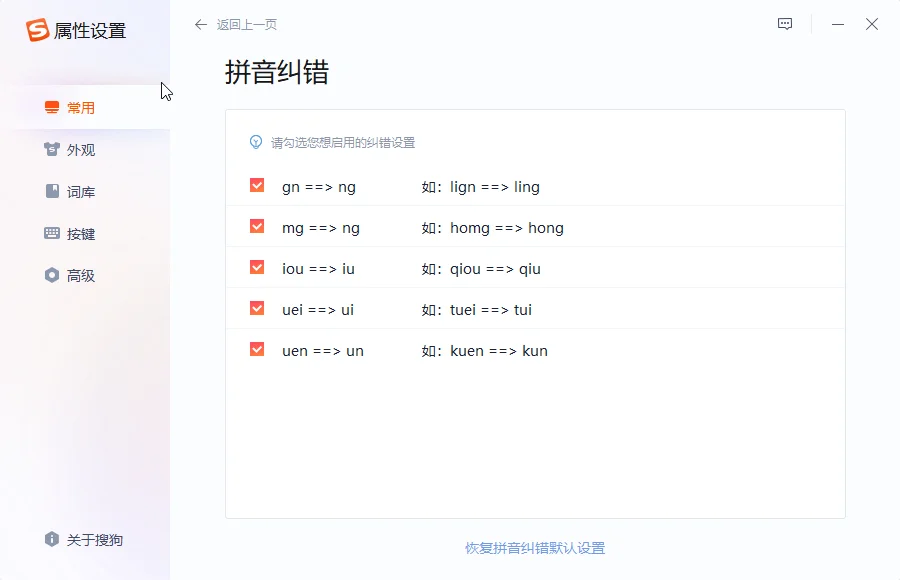
搜狗输入法的智能纠错原理
大数据驱动的语言模型
构建亿级数据语言模型: 搜狗输入法依托海量用户输入数据,构建覆盖广泛的语言模型,涵盖生活、工作、娱乐等多个领域。这些数据帮助系统理解常见词语搭配和用户习惯,从而准确判断输入内容是否存在偏差,提高整体输入的容错能力。
基于概率的词语预测机制: 系统通过统计语言模型计算词与词之间的共现概率,预测最可能出现的词组。当用户输入错误或不完整时,模型可根据上下文给出合理建议,从而实现自动纠错。这种预测模型还可根据输入长度动态调整输出结果,优化用户体验。
词库实时更新保持精准: 搜狗持续更新词库内容,特别是在应对网络热词、新兴术语等变化时,能快速响应并调整语言模型。结合用户上传的个性词库和云端词条数据,保持纠错能力的先进性和适应性,有效应对语言习惯的快速演变。
上下文语义分析技术
理解句意提升纠错质量: 搜狗采用自然语言处理技术,分析整句语义而非孤立词汇,使得纠错结果更贴合语境。即使拼音输入正确但语义不当时,也能结合句意进行智能修正,如将“我想吃苹果派对”纠正为“我想吃苹果派”,有效避免词语使用不当的问题。
引入深度学习理解语境: 借助循环神经网络(RNN)或Transformer等深度学习模型,系统能理解上下文中的词义关系,处理歧义词、长句和复杂语义结构。通过学习大量语言样本,模型可以不断提升对不同场景输入的识别与纠错能力。
动态适配用户表达习惯: 系统会根据用户历史输入记录不断优化语义识别模型,实现个性化的纠错处理。用户的用词偏好、行业术语和常用句式会被系统记录并融合进语义模型中,提升纠错效率的同时增强用户粘性和满意度。
拼写错误的自动识别机制
常见拼音输入错误的处理方式
识别拼音输入的键位误差: 用户在打字时常因手速快或按键位置相近而造成拼音输入错误,如将“shi”误输为“shiw”或“shj”。搜狗输入法内置键位容错算法,可自动识别这些键盘误差,并根据词语匹配概率推荐正确拼音对应的汉字。
拆分与合并拼音片段的识别: 在连续输入中,用户可能将拼音拼错或拼音组合不当,如“zhongguo”被误打为“zhon gguo”。搜狗输入法可以通过对拼音音节的分割与重组逻辑,智能判断拼写错误位置,纠正成正确的拼音结构,并还原出准确词语。
对多音节拼写顺序错误的修复: 一些用户输入拼音时可能将音节顺序搞混,比如输入“guozhong”实际想表达“zhongguo”。系统通过拼音逆向重组与上下文联想,推测出用户原意,并给出正确候选词,从而实现语义级别的拼写修复。
模糊拼音与相似音纠错策略
处理模糊拼音输入的场景: 用户可能因口音或拼音习惯输入模糊拼音,如“l”和“n”、“zh”和“z”混淆。搜狗输入法内置模糊音规则库,支持启用模糊拼音设置,使输入“nide”时也能正确显示“你的”,提升容错能力。
同音字和近音词的智能匹配: 相似发音的拼音如“qi”和“chi”、“en”和“eng”,常被混淆。搜狗通过上下文分析和语义概率模型,判断用户输入的是哪一类近音词,并将语义最契合的词排在首位,减少手动纠错需求。
自定义模糊音与反馈机制结合: 搜狗允许用户自定义模糊拼音规则,并结合使用过程中的输入选择行为,进一步优化模糊音识别策略。系统会自动学习用户在特定语境中偏好的拼音输入结果,从而在未来输入中优先展示相关候选词,增强个性化纠错能力。

错别字纠正的实现方式
汉字笔误与形近字分析
识别汉字输入时的笔画相似错误: 在拼音输入转为选字阶段,用户有时会因选错字或不熟悉某些汉字而输入笔误,例如将“谢”误选为“械”。搜狗输入法通过笔画结构数据库识别常见误选字,并结合上下文语义进行修正推荐。
处理形近字误用问题: 一些汉字在外形结构上非常相近,例如“未”与“末”、“日”与“目”,极易造成混淆。搜狗输入法内置形近字分析机制,对易混字进行标记,并结合整句内容判断是否为误用,从而提高选词准确性。
优化选词界面提升纠错效率: 为避免因视觉相似产生误选,搜狗在候选词界面中优化字体呈现与词频排序,使用户更容易识别并选择正确字词。同时系统也会根据用户历史行为动态调整误选概率,进一步提升错误识别能力。
基于词频与语义的纠错逻辑
高频词优先原则纠正错词: 搜狗根据中文语料中的词频数据判断用户最可能输入的词语。如果出现生僻词或搭配异常的字词组合,系统会用高频且语义合理的词自动替换,提高句子通顺度并降低误读风险。
上下文语义关系辅助识别: 系统通过分析前后词语间的逻辑与语义关系,判断当前词语是否符合语言习惯。例如输入“太阳从西边升起”时,“西边”虽拼写正确但语义异常,系统将识别该语句语义冲突并提供纠正建议。
结合用户习惯提升语义判断能力: 搜狗还会结合用户历史输入数据优化语义判断模型。如果某一用户经常输入特定术语或偏好表达方式,系统会优先考虑这些表达是否为正确用词,从而在保持语义准确的同时实现个性化纠错。
多场景下的纠错应用
聊天输入中的智能纠错表现
实时响应减少沟通误解: 在即时通讯中,用户输入节奏快、表达随意,常伴随拼写或语义错误。搜狗输入法在聊天场景下具备实时识别与纠错能力,能够在用户打字过程中迅速纠正拼音错误或错别字,确保信息表达准确。
适应口语化表达的纠错机制: 聊天语言往往带有大量网络流行词、缩写和口语化词汇,如“你咋啦”“肚子饿了”。搜狗通过对网络语言的语料学习,可自动识别并补全这些表达,避免将其误判为输入错误,提高沟通流畅度。
对表情与符号输入的智能兼容: 用户在聊天中常混合使用文字、表情、符号等内容,搜狗输入法能够正确处理这些混合输入场景,不会因特殊字符而干扰纠错逻辑。系统还可根据上下文推荐合适表情或短语,增强交流表达的丰富性。
文档编辑时的纠错辅助功能
提升长文本输入的准确率: 在文档撰写场景中,用户常输入较长、结构复杂的内容。搜狗输入法能进行全句级别的纠错处理,识别语病、拼写和语义不当等问题,帮助用户在写作过程中保持语言的规范性和准确性。
专业术语与行业词汇的识别能力: 对于涉及特定领域的文档写作,如法律、医疗、科技等,搜狗支持用户导入自定义词库,并自动识别常见术语,避免因术语输入错误而影响文档专业性与严谨性。
多平台协作下的同步纠错支持: 在办公软件、网页编辑器等不同平台中,搜狗均可稳定运行,提供一致的纠错体验。无论是写邮件、做汇报,还是在线协作文档,都能实现统一的智能纠错支持,降低人工校对负担。

搜狗输入法与其他输入法的纠错对比
与百度输入法纠错机制对比
语言模型训练数据差异: 搜狗输入法依托其庞大的搜索引擎数据和网页抓取内容构建语言模型,覆盖范围广、词汇更新快。而百度输入法虽然同样拥有大数据支持,但更偏重于基于搜索行为的短语预测,整体词频模型略显保守,导致在冷门词汇识别与纠错上稍逊一筹。
个性化纠错能力的表现差异: 搜狗通过长期记录用户输入习惯和纠错行为,自动优化词库与候选排序,形成独特的个性化模型。相比之下,百度输入法虽也支持个性词库,但其纠错机制更多依赖通用语言模型,个性定制能力不如搜狗灵活。
模糊拼音处理策略的差异化: 搜狗在模糊拼音识别方面加入更多细分场景和可自定义配置,例如用户可选择开启特定模糊拼音规则。而百度虽然支持模糊音识别,但设置较为固定,纠错结果在复杂语境下灵活性略低。
与微软拼音在语境理解上的差异
中文语境适配能力强弱对比: 微软拼音作为系统级输入法,其语境理解偏向基础逻辑匹配,注重输入准确性而非语言灵活性。搜狗输入法则注重自然语言的语义联想与语境推理,在面对较长句或模糊表达时能给出更符合中文表达习惯的词语推荐。
上下文纠错范围广度不同: 搜狗能基于整句分析词语关系,实现前后关联的纠错,例如识别“昨天吃了很多明天”中的语义冲突并推荐合理替换。而微软拼音大多基于词块级别纠错,对于复杂语义冲突识别能力有限,主要处理拼音层面的基础错误。
智能联想与词序调整能力差异: 在输入过程中,搜狗支持根据上下文动态调整候选词排序和联想词,例如用户输入“会议将”后系统优先推荐“召开”“推迟”等逻辑相关词;而微软拼音在智能联想方面偏保守,候选词多基于静态词频排列,缺乏对上下文变化的适应性。
搜狗输入法怎么提升拼写错误的识别准确率?
搜狗输入法如何识别错别字并自动纠正?
搜狗输入法在不同使用场景下如何进行智能纠错?